Apache Spark:核心概念,架构和内部
这篇文章介绍了Apache Spark的核心概念,如RDD,DAG,执行工作流,形成任务阶段和shuffle实现,还介绍了Spark Driver的体系结构和主要组件。
介绍
Spark是分布式数据处理的通用框架,提供用于大规模操作数据的功能API,内存数据缓存和跨计算的重用。它对分区数据应用了一组粗粒度转换,并依赖于数据集的谱系来在发生故障时重新计算任务。值得一提的是,Spark支持大多数数据格式,与各种存储系统集成,可以在Mesos或YARN上执行。
功能强大且简洁的API与丰富的库相结合,可以更轻松地大规模执行数据操作。例如,以Parquet格式执行Cassandra列族的备份和恢复:
def backup(path: String, config: Config) {
sc.cassandraTable(config.keyspace, config.table)
.map(_.toEvent)
.toDF()
.write
.parquet(path)
}
def restore(path: String, config: Config) {
sqlContext.read.parquet(path)
.map(_.toEvent)
.saveToCassandra(config.keyspace, config.table)
}
或运行差异分析,比较不同数据存储中的数据:
sqlContext.sql {
"""
SELECT count()
FROM cassandra_event_rollups
JOIN mongo_event_rollups
ON cassandra_event_rollups.uuid = cassandra_event_rollups.uuid
WHERE cassandra_event_rollups.value != cassandra_event_rollups.value
""".stripMargin
}
概念
Driver: 运行在客户端或者集群中,执行Application的main方法并创建SparkContext,调控整个应用的执行。
Application: 用户自定义并提交的Spark程序。
Job: 一个Application可以包含多个Job,每个Job由Action操作触发。
Stage: 比Job更小的单位,一个Job会根据RDD之间的宽依赖关系被划分为多个Stage,每个Stage中只存有RDD之间的窄依赖,即Transformation算子。
TaskSet: 每个Stage中包含的一组相同的Task。
Task: 最后被分发到Executor中执行的具体任务,执行Stage中包含的算子。
Partition: 原始数据会被按照相应的逻辑(例如jdbc和hdfs的split逻辑)切分成n份,每份数据对应到RDD中的一个Partition,Partition的数量决定了task的数量,影响着程序的并行度。
概括
Spark围绕弹性分布式数据集(RDD)和有向无环图(DAG)的概念构建,表示它们之间的转换和依赖关系。

Spark应用程序(通常指Driver Program和Application Master)由SparkContext和用户代码组成,用户代码与sc交互创建RDD并执行一系列转换以实现最终结果。然后将这些RDD转换转换为DAG并提交给Scheduler以在一组工作节点上执行。
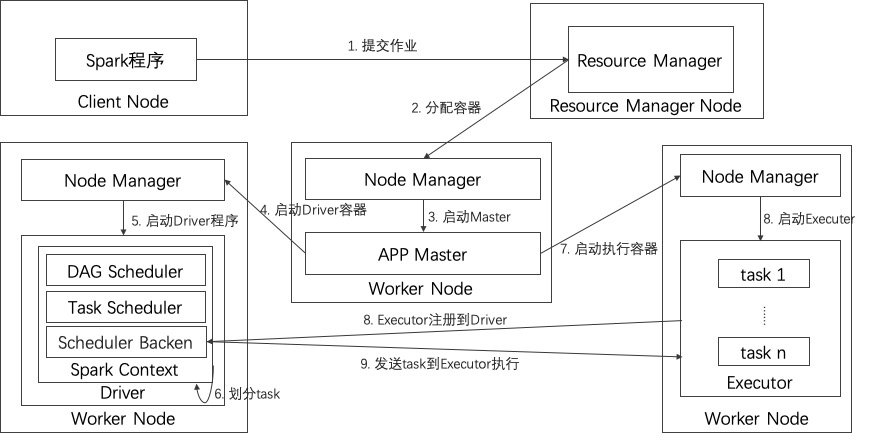
- 用户启动客户端,提交Spark程序给Resource Manager
- Resource Manager的scheduler分配一个container
- 在Node Manager在容器中启动Master的进程
- Master申请一个容器来启动Driver
- 在Node Manager在容器中启动Driver程序
- 每一个Action操作产生一个Job,提交给DAGScheduler,依据宽依赖就划分出stage,然后将包含一组task的stage提交给TaskScheduler,TaskScheduler对task进行调度,SchedulerBackend给等待分配计算资源的Task分配计算资源,即Executors
- SchedulerBackend发送task到具体的Executor执行
RDD:弹性分布式数据集
RDD可以被认为是具有故障恢复可能性的不可变并行数据结构。它为各种数据转换和实现提供API,以及控制元素的缓存和分区以优化数据放置。RDD既可以从外部存储创建,也可以从另一个RDD创建,并存储有关其父项的信息,以优化执行(通过流水线操作),并在发生故障时重新计算分区。
从开发人员的角度来看,RDD表示分布式不可变数据(分区数据+迭代器)和延迟操作(转换)。作为接口,RDD定义了五个主要属性:
//a list of partitions (e.g. splits in Hadoop)
def getPartitions: Array[Partition]
//a list of dependencies on other RDDs
def getDependencies: Seq[Dependency[_]]
//a function for computing each split
def compute(split: Partition, context: TaskContext): Iterator[T]
//(optional) a list of preferred locations to compute each split on
def getPreferredLocations(split: Partition): Seq[String] = Nil
//(optional) a partitioner for key-value RDDs
val partitioner: Option[Partitioner] = None
有一个方法调用期间创建的RDD的示例,
sparkContext.textFile("hdfs://...")
首先在内存中加载HDFS块,然后应用map()函数来过滤掉关键字并创建两个RDD:
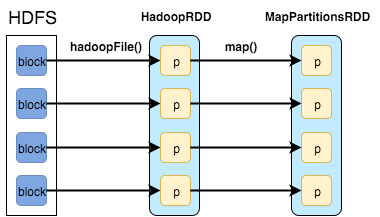
- HadoopRDD:
- getPartitions = HDFS blocks
- getDependencies = None
- compute = load block in memory
- getPrefferedLocations = HDFS block locations
- partitioner = None
- MapPartitionsRDD
- getPartitions = same as parent
- getDependencies = parent RDD
- compute = compute parent and apply map()
- getPrefferedLocations = same as parent
- partitioner = None
RDD操作
RDD上的操作分为3种:
- Transformations
- 将用户函数应用于分区中的每个元素(或整个分区)
- 将聚合函数应用于整个数据集(groupBy,sortBy)
- 引入RDD之间的依赖关系以形成DAG
- 提供重新分区的功能(repartition,partitionBy)
- Actions
- 触发作业执行
- 用于实现计算结果
- Persistence
- 显式地将RDD存储在内存,磁盘或堆外(缓存,持久)
- 检查点是否截断RDD谱系
//aggregate events after specific date for given campaign
val events =
sc.cassandraTable("demo", "event")
.map(_.toEvent)
.filter { e =>
e.campaignId == campaignId && e.time.isAfter(watermark)
}
.keyBy(_.eventType)
.reduceByKey(_ + _)
.cache()
//aggregate campaigns by type
val campaigns =
sc.cassandraTable("demo", "campaign")
.map(_.toCampaign)
.filter { c =>
c.id == campaignId && c.time.isBefore(watermark)
}
.keyBy(_.eventType)
.reduceByKey(_ + _)
.cache()
//joined rollups and raw events
val joinedTotals = campaigns.join(events)
.map { case (key, (campaign, event)) =>
CampaignTotals(campaign, event)
}
.collect()
//count totals separately
val eventTotals =
events.map{ case (t, e) => s"$t -> ${e.value}" }
.collect()
val campaignTotals =
campaigns.map{ case (t, e) => s"$t -> ${e.value}" }
.collect()
执行工作流程回顾
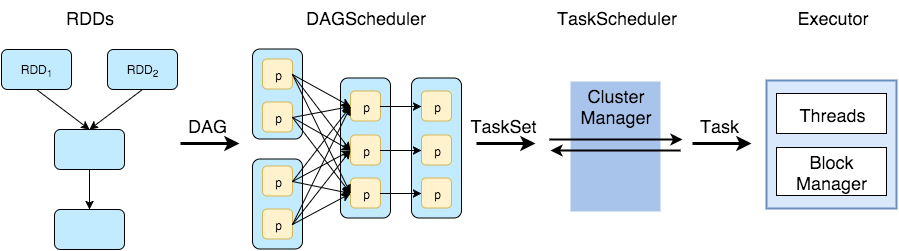
在深入研究细节之前,对执行工作流程的快速回顾:包含RDD转换的用户代码形成有向无环图,然后由DAG Scheduler分成任务段落(stage)。段落合并不需要shuffleing或repartition的任务。任务在worker上运行,然后结果返回到客户端。

基本上任何数据处理工作流程都可以定义为读取数据源,应用变换集合并以不同方式实现结果。转换在RDD之间创建依赖关系,在这里我们可以看到它们的不同类型。
依赖关系通常分为“窄”和“宽”:

- 窄依赖(pipelineable)
- 父RDD的每个分区最多由子RDD的一个分区使用
- 允许在一个群集节点上进行流水线执行
- 故障恢复更有效,因为只需要重新计算丢失的父分区
- 宽依赖(shuffle)
- 多个子分区可能依赖于一个父分区
- 要求所有父分区中的数据可用并在节点之间进行混洗
- 如果所有祖先都丢失了一些分区,则需要完全重新计算
将DAG拆分为stage
通过shuffle边界来划分Spark stage

具有窄依赖关系的RDD操作,如map()和filter(),在每个阶段操作中被一起流水线化为一组任务,其中shuffle依赖需要多个stage(一个用于输出一组map输出文件,另一个用于读取那些文件)。 最后,每个stage只对其他阶段具有shuffle依赖关系,并且可能在其中计算多个操作。这些操作的实际流水线操作发生在RDD.compute()各种RDD 的功能中。
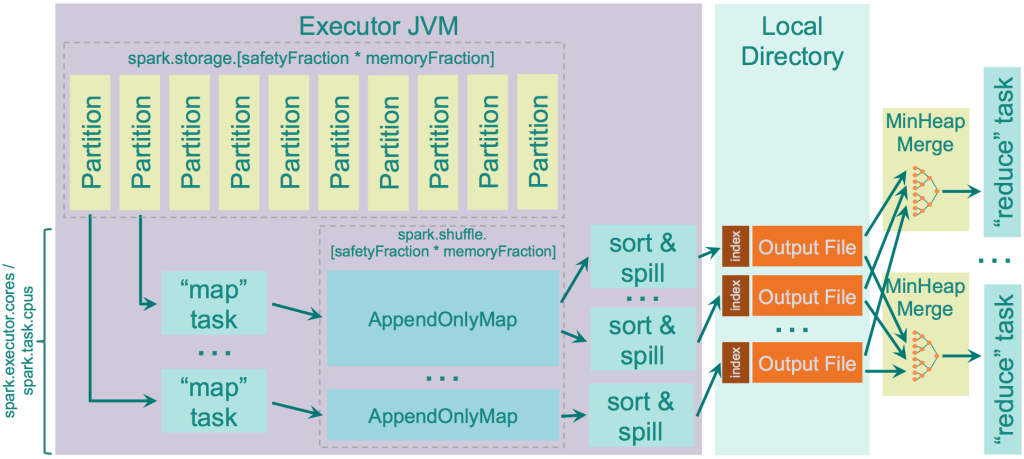
Hash Shuffle
在Spark 1.2.0之前,这是shuffle的默认选项(spark.shuffle.manager = hash)。但它有许多缺点,主要是由它创建的文件数量造成的 - 每个mapper任务为每个reducer创建单独的文件,导致集群上产生个MxR文件,其中M是mapper的数量,R是reducer的数量。使用大量的mapper和reducer会导致很大的问题,包括输出缓冲区大小,文件系统上打开文件的数量,创建和删除所有这些文件的速度。
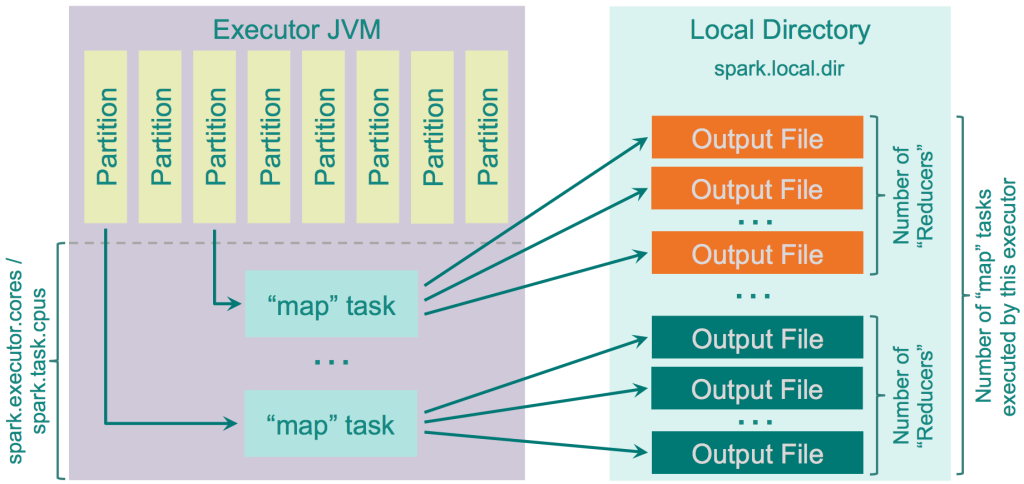
这个shuffler的逻辑非常愚蠢:它计算“reducers”的数量作为“reduce”侧的分区数量,为每个分区创建一个单独的文件,并循环遍历它需要输出的记录,它计算每个目标分区的目标分区,并将记录输出到相应的文件。
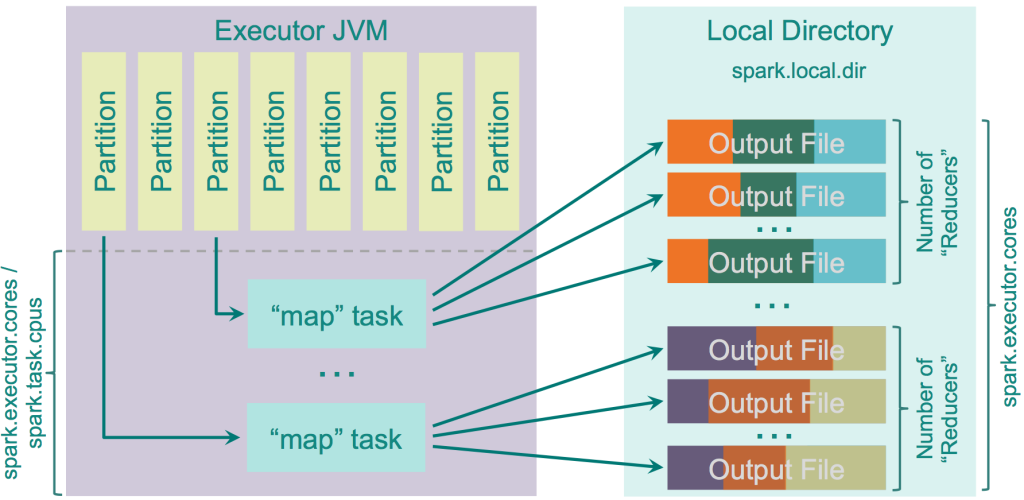
这个shuffler实现了一个优化,由参数“ spark.shuffle.consolidateFiles ”控制(默认为“false”)。当它设置为“true”时,将合并mapper输出文件。如果你的集群有E个Executor(YARN的“ -num-executors ”),并且每个Executor都有C个core(YARN的“ spark.executor.cores ”或“ -executor-cores ”),并且每个task都要求T个CPU(“ spark.task.cpus “),那么集群上的执行槽(slots)数量将是 E x C / T,并且在shuffle期间创建的文件数量将是E x C / T x R。有100个执行器,10个核心,每个核心为每个任务分配1个核心,46000个“reducer”,它可以让你从20亿个文件减少到4600万个文件,这在性能方面要好得多。此功能以相当简单的方式实现:它不是为每个reducer创建新文件,而是创建一个输出文件池。当map任务开始输出数据时,它会从此池中请求一组R个文件。完成后,它会将R个文件组返回到池中。由于每个执行程序只能并行执行C / T任务,因此它只会创建C / T 组输出文件,每组都是R个文件。在第一次C / T之后,并行“map”任务已完成,下次每个“map”任务都将重用此池中的现有组。
优点:
- 快速 - 根本不需要排序,不维护哈希表
- 没有用于排序数据的内存开销
- 没有IO开销 - 数据只写入硬盘一次,只读一次
缺点:
- 当分区数量很大时,由于大量输出文件,性能开始下降
- 写入文件系统的大量文件会导致IO偏向随机IO,这通常比顺序IO慢100倍
在shuffle ShuffleMapTask将块写入本地驱动器期间,然后下一阶段的任务通过网络获取这些块。
- Shuffle Write
- 在分区之间重新分配数据并将文件写入磁盘
- 每个hash shuffle任务为每个“reduce”任务创建一个文件
- sort shuffle任务创建一个文件,其中区域分配给reducer
- sort shuffle使用内存排序和溢出到磁盘以获得最终结果
- Shuffle Read
- 获取文件并应用reduce()逻辑
- 如果需要数据排序,则在“reducer”侧对任何类型的shuffle进行排序
shuffle排序
在“map”端对数据进行排序,但是在“reduce”端不做这次排序结果的合并 - 如果需要对数据排序,它只需重新排序数据。
如果没有足够的内存来存储整个“map”输出怎么办?需要将中间数据溢出到磁盘。参数spark.shuffle.spill负责启用/禁用溢出,默认情况下启用溢出。如果你要禁用它并且没有足够的内存来存储“map”输出,你只会得到 OOM 错误,所以要小心。
Spark内部使用AppendOnlyMap结构将“map”输出数据存储在内存中。有趣的是,Spark使用自己的散列表Scala实现,该散列表使用开放散列并使用二次探测将键和值存储在同一个数组中。
此哈希表允许Spark在此表上应用“combiner”逻辑 - 为现有键添加的每个新值都通过“combine”逻辑与现有值进行,并且“combine”的输出存储为新值。
当溢出发生时,它只是在存储在这个AppendOnlyMap中的数据之上调用“sorter”,它在它上面执行TimSort,并且这些数据被写入磁盘。当溢出发生或没有更多映射器输出时,将分类输出写入磁盘,即保证数据到达磁盘。
每个溢出文件分别写入磁盘,只有在“reducer”请求数据并且合并是实时的时才执行它们的合并,即它不像在Hadoop MapReduce中那样调用“on-disk merger”。它只是动态地从许多单独的溢出文件中收集数据,并使用Java PriorityQueue类实现的Min Heap将它们合并在一起。