YARN
YARN将Jobtracker的职能划分为多个独立的实体,从而改善了经典的MapReduce面临的扩展瓶颈问题。Jobtracker的作用:
- 负责作业调度和任务进度监视
- 追踪任务、重启失败或过慢的任务和进行任务登记,例如维护计数器总数

YARN将这两种角色划分为两个独立的守护进程:
- 资源管理器(Resource Manager):负责管理所有应用程序计算资源的分配
- 应用管理器(Application Master):负责应用程序相应的调度和协调
容器(containers)是YARN为资源隔离而提出的框架,每个容器都有特定的内存上线,每一个task对应一个container,且只能在该container中运行。容器由集群节点上运行的节点管理器(Node Manager)监视,以确保应用程序使用的资源不会超过分配给它的资源。Node Manager管理每个节点上的资源和任务,主要有两个作用:
- 定期向Resource Manager汇报该节点的资源使用情况和各个container的运行状态
- 接收并处理Application Master的作业启动、停止等请求
Hadoop on Yarn运行MR的过程
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 启动ApplicationMaster;
- 由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
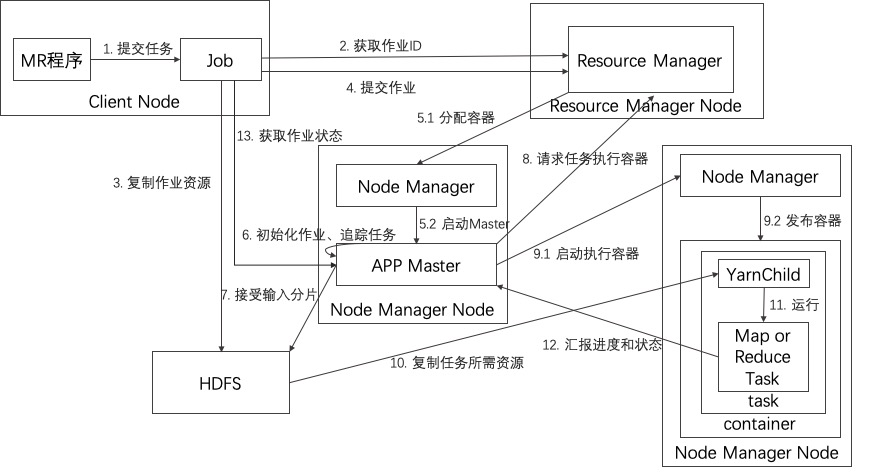
- 客户端运行作业
- 从Resource Manager获取新的作业ID
- 将作业资源(包括作业JAR、配置和分片信息)复制到HDFS
- 调用Resource Manager的submitApplication()方法提交任务
- 资Resource Manager的scheduler分配一个container,然后Resource Manager在Node Manager的管理下在容器中启动Application Master的进程
- Application Master对作业进行初始化,保持作业进度的跟踪,因为它将接受来自任务的进度和完成报告
- Application Master接受来自HDFS的输入分片。对每一个分片创建一个map任务对象以及由mapreduce.job.reduces属性确定的多个reduce任务对象
- Application Master为该作也中的所有map任务和reduce任务想资源管理器请求容器
- 一旦Resource Manager的scheduler为task分配了container,Application Master就通过Node Manager通信来启动container
- 在运行任务之前,首先将任务需要的资源本地化,包括作业的配置、JAR文件和所有来自分布式缓存的文件
- 运行map任务或reduce任务
- task每三秒钟向Application master汇报进度和状态
- 客户端每5秒钟来检查作业是否完成
shuffle和排序
MapreduceR确保每个reducer的输入都是按键排序的。系统执行排序的过程(即将map输出作为输入传给reduce)称为shuffle。在许多方面来看,shuffle是MapReduce的心脏,是奇迹发生的地方。
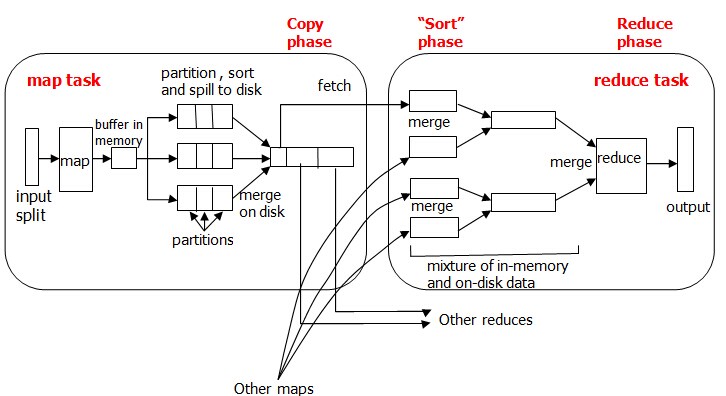
map端
对每一个block创建一个map任务对象,每个map任务都有一个环形内存缓冲区(默认100M)用于存储任务输出。一旦缓冲内容达到阈值(默认0.8),一个后台程序便开始拔出内容溢出到磁盘。在溢出写到磁盘过程中,map输出继续写到缓冲区,但如果此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成。
在写入磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的partition。在每个partition中,后台线程按键进行内排序,如果有一个combiner(本质是一个reducer),他就在排序后的输出上运行,使得map输出结果更紧凑,因此减少写到磁盘的数据和传递给reducer的数据。
每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),因此在map任务写完其最后一个输出记录之后,会有几个溢出文件。在任务完成之前,如果溢出文件大于3个,将会再次调用combiner将溢出文件合并成一个已分区的且已排序的输出文件。
reduce端
reduce任务需要集群上若干个map任务的map输出作为输入。只要有一个map任务完成,reduce任务就开始复制其输出,这就是reduce任务的复制阶段。随着磁盘上副本的增多,后台线程会将它们合并为更大的、排好序的文件。复制完所有的map输出后,reduce任务进入排序阶段,这个阶段将合并map输出,维持其顺序排序。
reduce阶段,直接把数据输入reduce函数,直接输出到hdfs。