Kylin Data Summit 论坛交流总结
数据开发平台
数据开发平台作为数据存储、开发、分析及业务赋能的重要平台,一般有如下模块组成:
数据存储
- 分布式存储 HDFS/S3
- 数据仓库 Hive/Redshift/HBase
- 事件流 Kafka/Klnesls
数据搜索
- 即时SQL查询
- 多种查询引擎
- 文件浏览
- 图形化结果展示
- 查询历史
数据开发
- Jupyter Notebook
- Python开发
- 模型开发
- 数仓开发
- 模型共享
数据管理
- 元数据管理
- 库表级查询权限控制
- 敏感信息脱敏处理
- DML、DDL、DCL权限控制
- 数据治理
调度配置
- 工作流配置
- 血缘关系
- 依赖自动解析
- 调度配置管理
- DAG视图
数据湖与数据仓库
数据湖和数据仓库是可以收集和管理所有数据的两种方式,但两者之间的区别明显。
数据湖
数据湖作为一个集中的存储库,可以在其中存储任意规模的所有结构化和非结构化数据。在数据湖中,可以存储数据不需要对其进行结构化,就可以运行不同类型的分析。
数据湖的创建通常没有特定的目的。它包含来自各种数据源的所有源数据,这使得它在潜在的用例中更加灵活。数据湖通常建立在低成本的商品硬件上,这使得它在经济上行存储TB级甚至PB级数据。
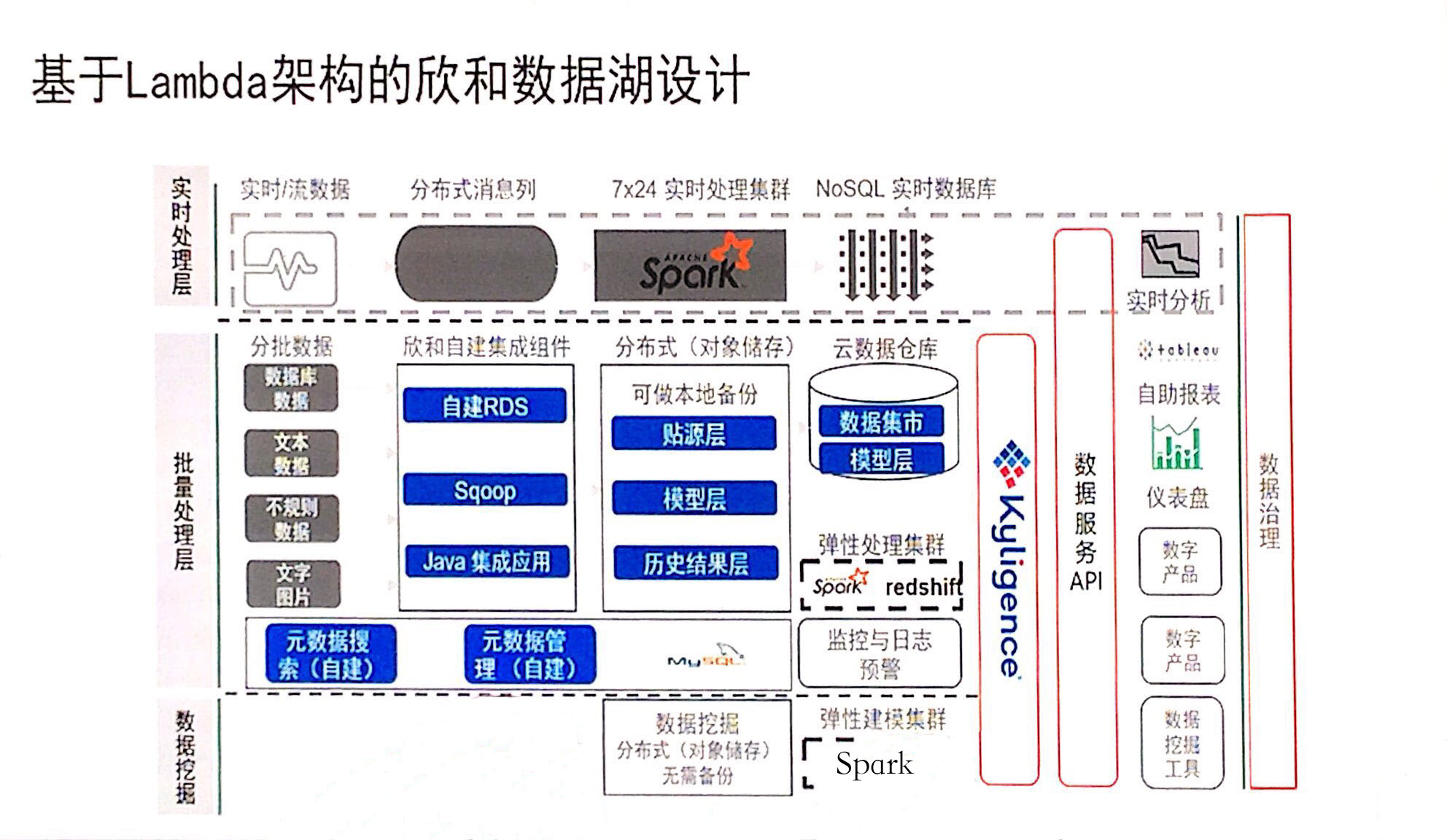
数据仓库
数据仓库,也称为企业数据仓库,是一种数据存储系统,它将来自不同来源的结构化数据聚合起来,用于业务智能领域的比较和分析。数据仓库一整套包括了etl、调度、建模在内的完整的理论体系。此外,仓库中的数据往往是高度标准化和非常“干净”的。
数仓的优势
清晰数据结构
每一个数据分层都有它的作用域,这样在使用表的时候能更方便地定位和理解。
数据血缘追踪
简单来讲可以这样理解,我们最终给业务呈现的是一个能直接使用的数据集市,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
把复杂问题简单化
讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
屏蔽原始数据的异常。
屏蔽业务的影响
不必改一次业务就需要重新接入数据。
数仓模型
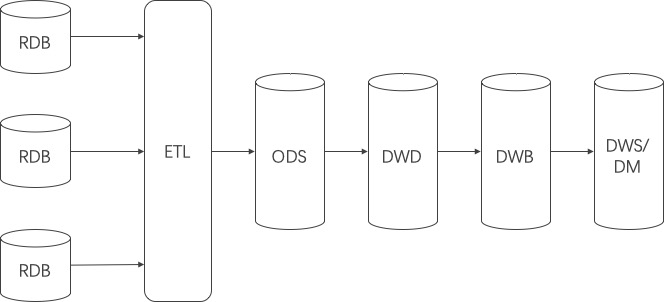
ODS(Operational Data Store)
操作性数据,是作为数据库到数据仓库的一种过渡,ODS的数据结构一般与数据来源保持一致,便于减少ETL的工作复杂性。
DWD(data warehouse detail)
细节数据层,是业务层与数据仓库的隔离层,是最接近数据源中数据的一层,数据源中的数据进过ETL后装入本层。这一层主要解决一些数据质量问题和数据的完整度问题。
DWB(data warehouse base)
基础数据层, 是数据仓库的主体,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。通常按照主题建立各种数据模型,如:星形或雪花结构等;
DWS(data warehouse service)
服务数据层又称数据集市DM(date market),基于DWB上的基础数据,整合汇总成分析某一个主题域的服务数据,一般是宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
数据平台架构及应用
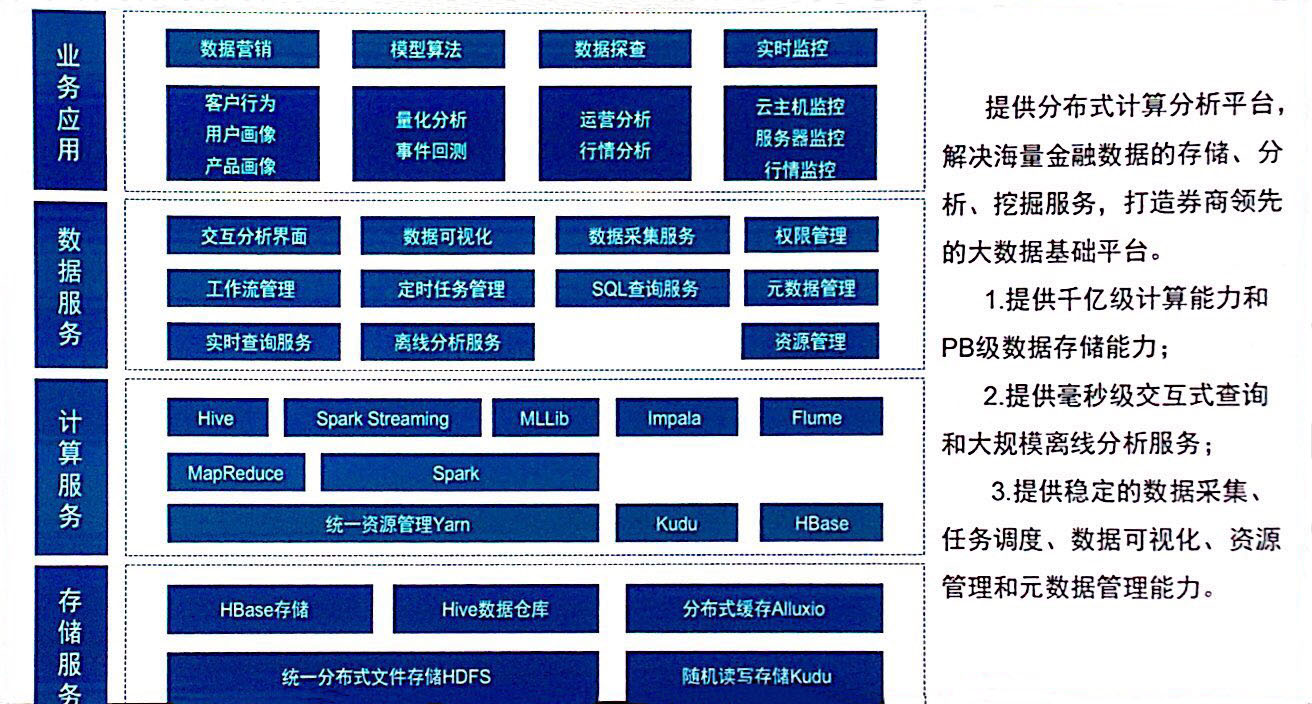
总结
在建设数仓之前,需要对MPP数据库进行选型,可以选择GBase,HBase,Hive等。如果选择商用采购,以上都可以进行对比选型;若采用自建,首先需要落地数据平台并保证平台的稳定性。
在基础数据平台完善的情况下,需要对业务指标进行数仓建模,对数据进行分层操作。
对于即时查询可以采用HBase,对离线查询可以采用Hive;如对数据查询有特别要求的,可以采用分布式内存系统Alluxio进行数据缓冲。
在数据仓库完备的情况下,对报表台账等业务分析系统可以实现自动化。
在搭建数据仓库同时可以搭建数据湖,数据湖应该包含各个系统各种类型的数据,所有提数和分析任务都应该在数据湖中进行,隔离对线上系统的影响。
在各源头数据汇集到一个平台后,可以考虑数据赋能的应用,如用户画像,运营分析,行情预见等。