查找算法算法实现
顺序查找
说明:顺序查找适合于存储结构为顺序存储或链接存储的线性表。 基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败。 时间复杂度:O(n)
public int sequenceSearch(Integer[] array, Integer value) {
for (int i = 0; i < array.length; i++) {
if (array[i] == value) {
return i;
}
}
return -1;
}
二分查找
说明:元素必须是有序的,如果是无序的则要先进行排序操作。
基本思想:也称为是折半查找,属于有序查找算法。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。 时间复杂度:O(log2n) 注:折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,折半查找能得到不错的效率。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。
public int binarySearch(Integer[] array, Integer value, int low, int high) {
int mid = low + (high - low) / 2;
if (array[mid] == value)
return mid;
else if (array[mid] > value)
return binarySearch(array, value, low, mid - 1);
else if (array[mid] < value)
return binarySearch(array, value, mid + 1, high);
return -1;
}
插值查找
与二分查找比较,比例参数1/2改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
mid = low + (value - array[low]) / (array[high] - array[low]) * (high - low)
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。 注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。 时间复杂度均:O(log2n)
public int insertionSearch(Integer[] array, Integer value, int low, int high) {
int mid = low + (value - array[low]) / (array[high] - array[low]) * (high - low);
if (array[mid] == value)
return mid;
else if (array[mid] > value)
return binarySearch(array, value, low, mid - 1);
else if (array[mid] < value)
return binarySearch(array, value, mid + 1, high);
return -1;
}
斐波那契查找
斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(从第三个数开始,后边每一个数都是前两个数的和)。然后我们会发现,随着斐波那契数列的递增,前后两个数的比值会越来越接近0.618,利用这个特性,我们就可以将黄金比例运用到查找技术中。
基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
时间复杂度:O(log2n)
public int getFibonacci(double n) {
double fibonacci = 1 / Math.sqrt(5) * (Math.pow((1 + Math.sqrt(5)) / 2, n) - Math.pow((1 - Math.sqrt(5)) / 2, n));
return (int) (fibonacci + 0.5);
}
public int fibonacciSearch(Integer[] array, Integer value, int low, int high) {
int k = 0;
// 寻找length位于斐波那契数组的位置
int length = high - low + 1;
while (length > getFibonacci(k) - 1)
k++;
int mid = low + getFibonacci(k - 1) - 1;
if (value == array[mid])
return mid;
else if (value < array[mid])
return fibonacciSearch(array, value, low, mid - 1);
else if (value > array[mid])
return fibonacciSearch(array, value, mid + 1, high);
return -1;
}
分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
算法思想:将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
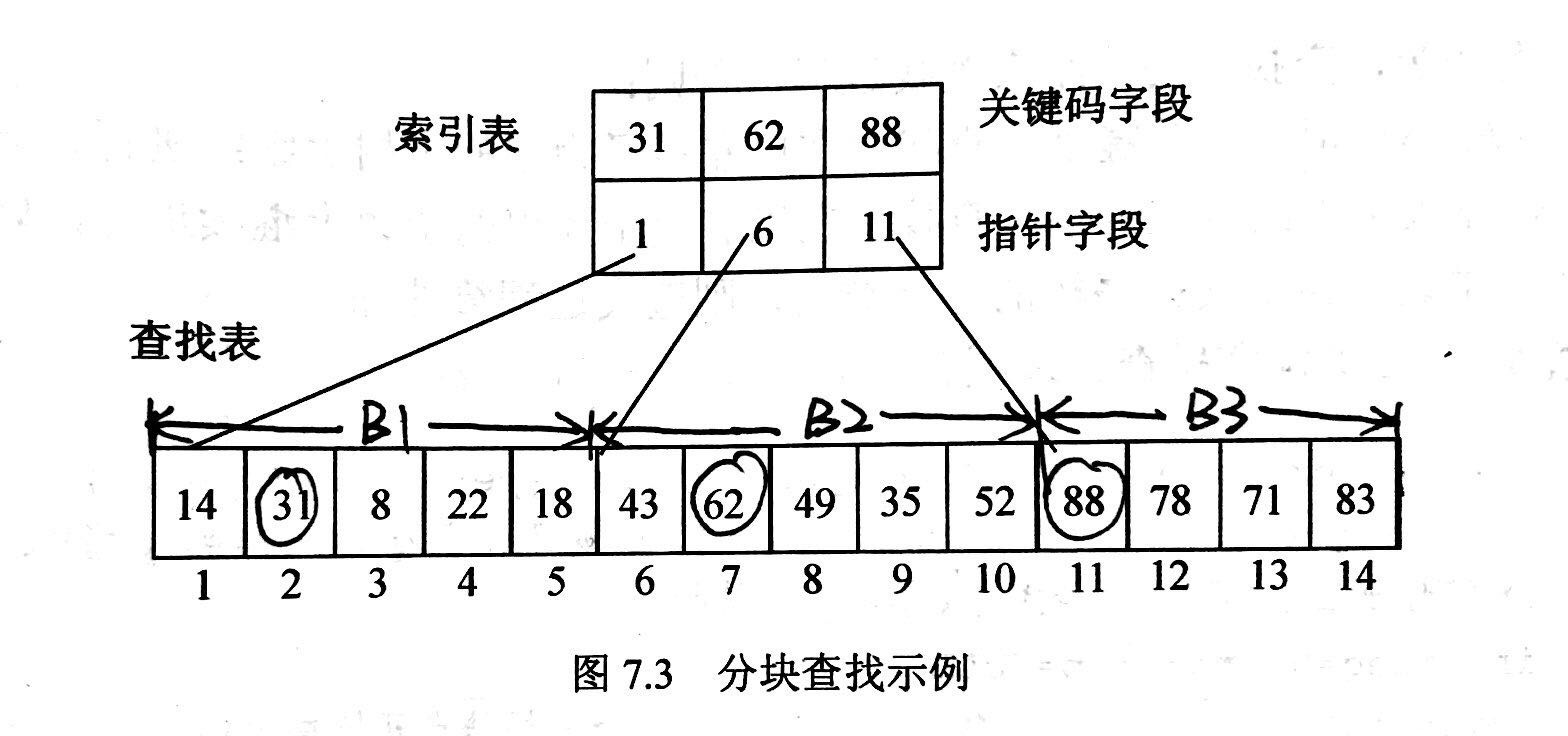
算法流程:
- 先选取各块中的最大关键字构成一个索引表;
- 查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。