Spark、Strom、Flink和Beam的技术选型
Spark streaming、Storm、Flink和Beam都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂程度。
Storm
Storm中的核心抽象是“stream”。流是无限制的元组序列。Storm提供了用于以分布式且可靠的方式将流转换为新流的原语。例如,可以将推文流转换为趋势主题流。
Storm为进行流转换提供的基本原语是“spouts”和“bolts”。spouts和bolts具有您实现的接口,以运行特定于应用程序的逻辑。
spout是流的源头。例如,spout可能会从Kestrel队列中读取元组并将其作为流发出。或者,spout可能会连接到Twitter API并发出一连串推文。
bolt消耗任何数量的输入流,进行一些处理,并可能发出新的流。复杂的流转换,就像从一条推文流中计算趋势主题流一样,需要多个步骤,因此需要多个步骤。bolt可以执行任何功能,包括运行功能,过滤元组,进行流聚合,进行流联接,与数据库对话等等。
spout和bolt网络打包成一个“拓扑”,这是提交给Storm集群以执行的顶层抽象。拓扑是流转换的图形,其中每个节点都是spout和bolt。图中的边缘指示哪些bolt正在订阅哪些流。当spout或bolt向流中发送元组时,它将元组发送给订阅该流的每个bolt。
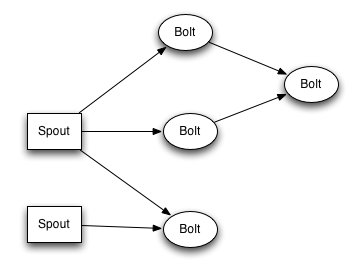
拓扑中节点之间的链接指示元组应如何传递。例如,如果Spout A和 Bolt B之间存在链接,从Spout A到Bolt C之间存在链接,并且从Bolt B到Bolt C之间存在链接,则每次Spout A发出一个元组时,都会将该元组发送到两个Bolt B和Bolt C。Bolt B的所有输出元组也将进入Bolt C。
Storm拓扑中的每个节点都并行执行。在拓扑中,您可以指定每个节点要多少并行度,然后Storm将在集群中产生该数量的线程来执行。
拓扑将永远运行,或者直到您杀死它为止。Storm将自动重新分配所有失败的任务。此外,Storm保证即使机器宕机和消息丢失也不会丢失数据。
Beam
Apache Beam是一个开放源代码统一模型,用于定义批处理和流数据并行处理管道。使用一种开源的Beam SDK,您可以构建一个定义管道的程序。然后,该管道由Beam支持的分布式处理后端之一执行,这些后端包括Apache Apex,Apache Flink,Apache Spark和Google Cloud Dataflow。
Beam对于令人尴尬的并行数据处理任务特别有用,在该任务中,问题可以分解为许多较小的数据束,可以独立和并行处理。还可以将Beam用于提取,转换和加载(ETL)任务以及纯数据集成。这些任务对于在不同的存储介质和数据源之间移动数据,将数据转换为更理想的格式或将数据加载到新系统上非常有用。
Beam模型允许跑步者以不同的方式执行管道。跑步者的选择可能会导致各种影响。
运行程序可能出于通信目的和其他原因(例如持久性)而在机器之间序列化元素。Runner可以决定以多种方式在转换之间转移元素,例如:
- 将元素路由到工作程序以作为分组操作的一部分进行处理。这可能涉及序列化元素,并按其键对它们进行分组或排序。
- 在worker之间重新分配元素以调整并行度。这可能涉及序列化元素并将其传达给其他worker。
- 在侧面输入中使用元素ParDo。这可能需要序列化元素并将其广播给执行该操作的所有工作人员ParDo。
- 在同一工作程序上运行的转换之间传递元素。这可以使Runner避免序列化元素;相反,Runner可以只传递内存中的元素。
运行程序可能会序列化和保留元素的某些情况是:
- 当作为有状态的一部分使用时DoFn,运行程序可以将值持久化到某种状态机制。
- 提交处理结果时,运行程序可以将输出保留为检查点。
将集合分为多个包是任意的,并由Runner选择。这使Runner可以在每个要素之后的持久结果之间进行选择,并在出现故障时必须重试所有结果之间选择适当的中间立场。例如,流处理器可能更喜欢处理和提交小包,而批处理器可能更喜欢处理较大的包。
如果束中的元素处理失败,则整个束都会失败。捆绑中的元素必须重试(否则整个管道将失败),尽管不需要使用相同的捆绑重试它们。因为在处理输入包中的元素时遇到了故障,所以我们不得不重新处理输入包中的所有元素。这意味着Runner必须丢弃整个输出包,因为它将包含所有结果。
Flink
Apache Flink是一个框架和分布式处理引擎,用于对无限制和有限制的数据流进行有状态的计算。Flink被设计为可以在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
Apache Flink擅长处理无边界和有边界的数据集。对时间和状态的精确控制使Flink的运行时能够在无限制的流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部进行处理,从而产生出色的性能。
Flink旨在运行任何规模的有状态流应用程序。将应用程序并行化为可能在群集中分布并同时执行的数千个任务。因此,应用程序几乎可以利用无限数量的CPU,主内存,磁盘和网络IO。而且,Flink易于维护非常大的应用程序状态。它的异步和增量检查点算法可确保对处理延迟的影响最小,同时可保证一次状态一致性。
每个非单独事件的流应用程序都是有状态的,即,仅对单个事件处理的应用程序不需要状态。任何运行基本业务逻辑的应用程序都需要记住事件或中间结果,以便在以后的某个时间点访问它们,例如,在收到下一个事件时或在特定的持续时间之后。
时间是流应用程序的另一个重要组成部分。大多数事件流具有固有的时间语义,因为每个事件都是在特定的时间点产生的。此外,许多常见的流计算都是基于时间的,例如窗口聚合,会话化,模式检测和基于时间的联接。流处理的一个重要方面是应用程序如何测量时间,即事件时间与处理时间之差。
一些用户报告了其生产环境中运行的Flink应用程序的性能,例如
- 每天处理数万亿事件
- 维护多个TB状态
- 运行在数千个内核上
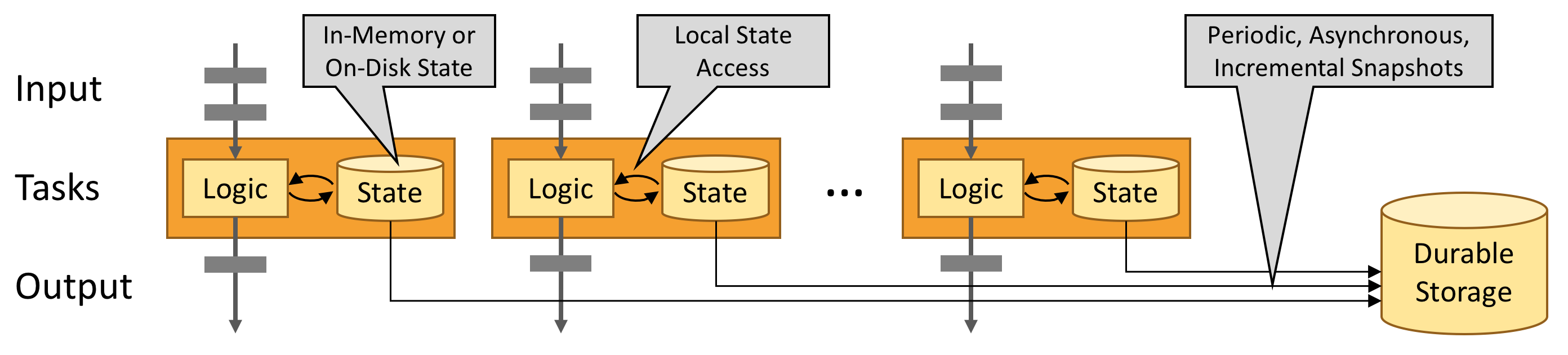
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保持在内存中,或者,如果状态大小超出可用内存,则始终保持在访问有效的磁盘数据结构中。因此,任务通过访问通常处于内存中的状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期将本地状态异步指向持久性存储来确保出现故障时一次准确的状态一致性。
Sparkassets/2019-09/
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从像Kafka,Flume,Kinesis,或TCP sockets许多来源摄入,并且可以使用与像高级别功能表达复杂的算法来处理map,reduce,join和window。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。实际上,可以在数据流上应用Spark的机器学习和图形处理算法。
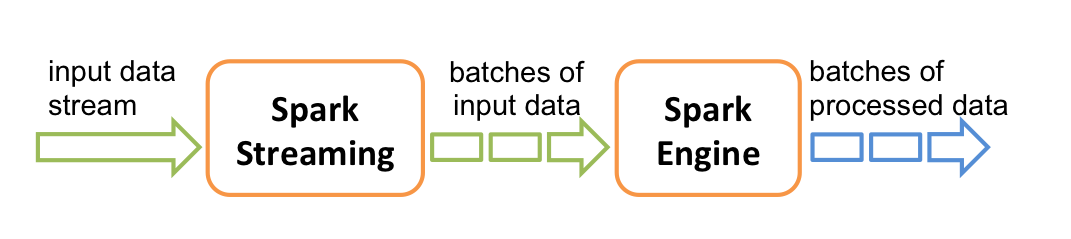
在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批处理,然后由Spark引擎进行处理,以生成批处理的最终结果流。
Spark Streaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka,Flume和Kinesis等来源的输入数据流来创建DStream,也可以通过对其他DStream应用高级操作来创建DStream。在内部,DStream表示为RDD序列。
Spark Streaming还提供了窗口计算,可让您在数据的滑动窗口上应用转换。下图说明了此滑动窗口。
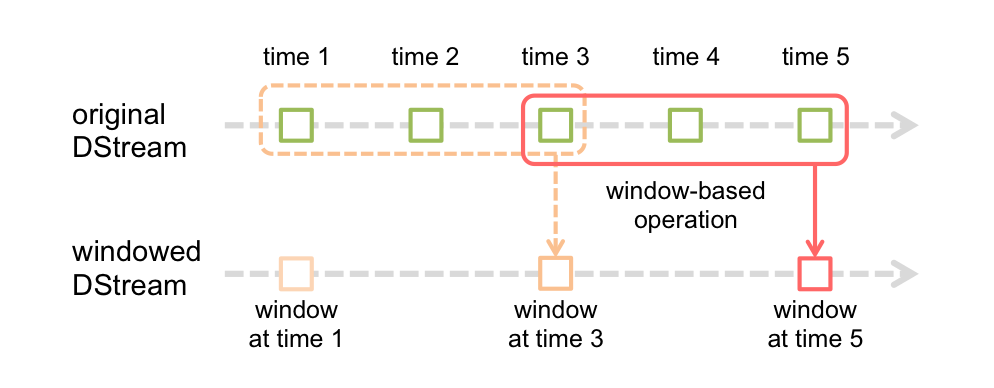
如该图所示,每一个窗口时间片在源DSTREAM,落入窗口内的源RDDS被组合及操作,以产生加窗DSTREAM的RDDS。在这种特定情况下,该操作将应用于数据的最后3个时间单位,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
- 窗口长度 - 窗口的持续时间。
- 滑动间隔 -进行窗口操作的间隔。
这两个参数必须是源DStream的批处理间隔的倍数.
值得一提的是,可以轻松地在Spark Streaming中执行各种类型的联接。在每个批处理间隔中,由生成的RDD stream1将与生成的RDD合并在一起stream2。你也可以做leftOuterJoin,rightOuterJoin,fullOuterJoin。此外,在流的窗口上进行连接通常非常有用。
应用场景对比
storm属于真正的流式处理,低延迟(ms级延迟),高吞吐,且每条数据都会触发计算。适用于时效性要求极高,但计算逻辑简单的应用。窗口计算需要独立设计,没有现成函数。
Beam对Spark和Flink的计算框架做了统一,将是大势所趋,但该项目目前还不够成熟,应用于生产环境的场景较少,社区活跃量不如spark和flink。
spark属于批处理转化为流处理即将流式数据根据时间切分成小批次进行计算,对比与storm而言延迟会高于0.5s(s级延迟),但是性能上的消耗低于storm。流式计算是批次计算的特例。相比于storm ,spark和flink两个都支持窗口和各种算子,减少了不少的编程时间。
flink支持通过event time来控制窗口时间,支持乱序时间和时间处理。对于spark而言的优势就是机器学习,如果我们的场景中对实时要求不高可以考虑spark,但是如果是要求很高就考虑使用flink。
总结
基于目前的业务场景,我们主要选择spark作为批处理和实时流处理框架,在对实时性要求较高的应用选择Flink,原因有如下几点:
- Spark可以做批处理和流处理任务,统一了数据处理框架。
- Ambari可以集成Spark环境,在Ambari上可以对Spark做同一监控和运维管理。
- Spark支持丰富的机器学习算法,对业务的AI智能化有良好的支持。
- 目前分析工作可以接受秒级响应。
- 开发人员对Spark开发有成熟的开发经验,学习成本较低,对优化和排错有丰富的经验。