HBase行键设计
行键设计
HBase有两种基本的键结构:行键和列键。两者都可以存储有意义的信息,一种是键本身存储的内容,另一种是键的排列顺序。
概念
HBase 的表中数据分隔主要是使用列族(column family)而不是列,并非列式存储。
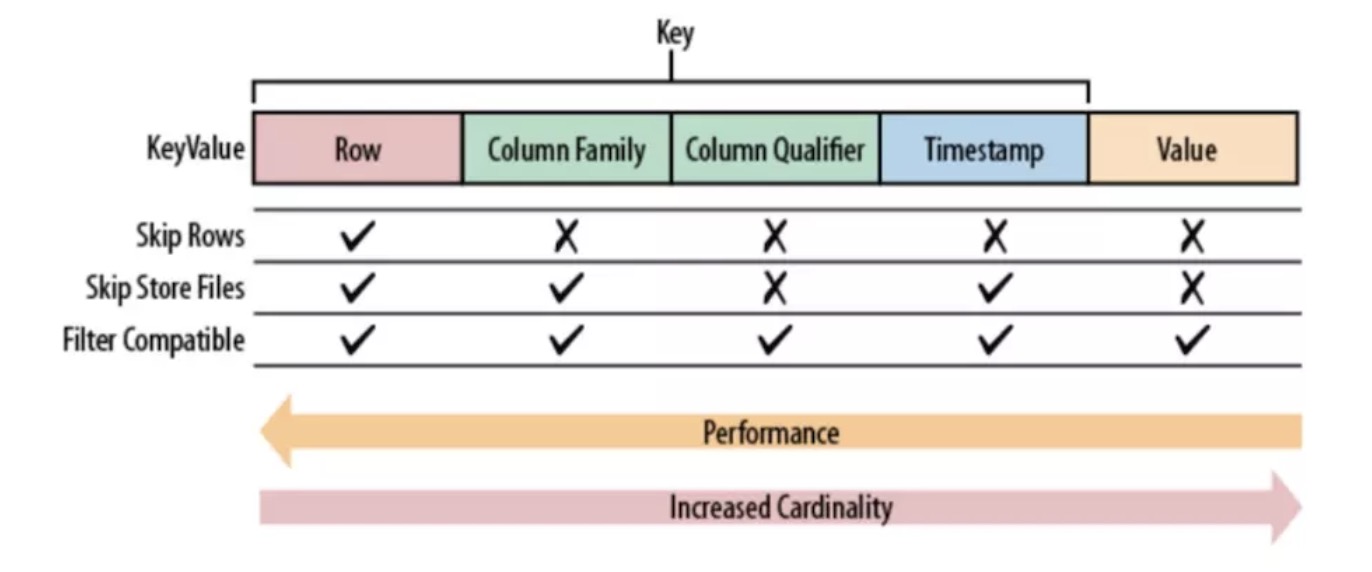
使用不同字段对筛选的性能影响大小。筛选的效率从左至右明显下降,所以在 KeyValue 设计时,可以考虑把更重要的筛选信息移动位置
高表与宽表
HBase 的表可以设计为高表(tall-narrow table)和宽表(flat-wide table)两类。前者行多列少,后者行少列多。根据之前介绍的 KeyValue 的信息筛选效率,应该尽量的将需要查询的维度或信息存储在行键中,筛选的效率是最高的。此外,HBase 按行进行数据分片,因此高表更有优势。
时间序列
当处理流式数据时,最常见的数据就是按时间序列组织的数据。数据可能来自传感器,监控系统,实时交易系统等。这些数据的特点是行键都代表了事件发生的时间。由于 HBase 的数据组织方式,这样的数据在存储时会出现一个问题:数据热点问题,由于业务的特性在某些特定范围内数据量会非常大,会造成 Region 的数据量分布不均匀,同时数据写入会集中到特定的 Region 上,导致性能下降。 为了解决这类问题,需要将数据能够更均匀的分散到各个 Region 上,在此介绍几种方法:
salting 方式
可以使用 salting 前缀来保证数据分散到所有 Region 上:
byte prefix = (byte) (Long.hashCode(timestamp) % <number of region servers>);
byte[] rowkey = Bytes.add(Bytes.toBytes(prefix), Bytes.toBytes(timestamp);
上面前缀的计算方法,利用时间戳的离散哈希值,并假设 RegionServer 数量固定的情况,能够使数据均匀的分布在各个 Region 上。 缺点是,当用户要扫描一个连续的范围时,可能需要对每个region服务都发器请求,但是可以多线程并行读取的方式提高查询吞吐量。
字段交换/提升权重
如果行键设计包含了多个字段,可以将时间戳字段(如果是一个字段,或其他不离散的第一个字段)在不影响业务的前提下,调整位置。如果行键只包含时间戳,可以将其他字段提取出来放到行键的第一位。
随机化
另一种完全不同的方式是将行键随机化(哈希或MD5算法):
byte[] rowkey = MD5(timestamp)
随机化的方式很适合每次只读取一行数据的应用。如果用户的数据不需要连续扫描而只需随机读取,用户就可以使用这种策略。